Subtyping Salmonella data with bio_hansel
This is a quick tutorial on how to use IRIDA to analyze data with the bio_hansel pipeline.
Tutorial Data
The data for this tutorial comes from the EMBL-EBI ENA sequencing run sample SRR1203042 (please download the forward reads and reverse reads).
It is assumed the forward reads and reverse reads in fastq.gz format have been uploaded into an appropriate sample as described in the Web Upload Tutorial.
Adding Samples to the Cart
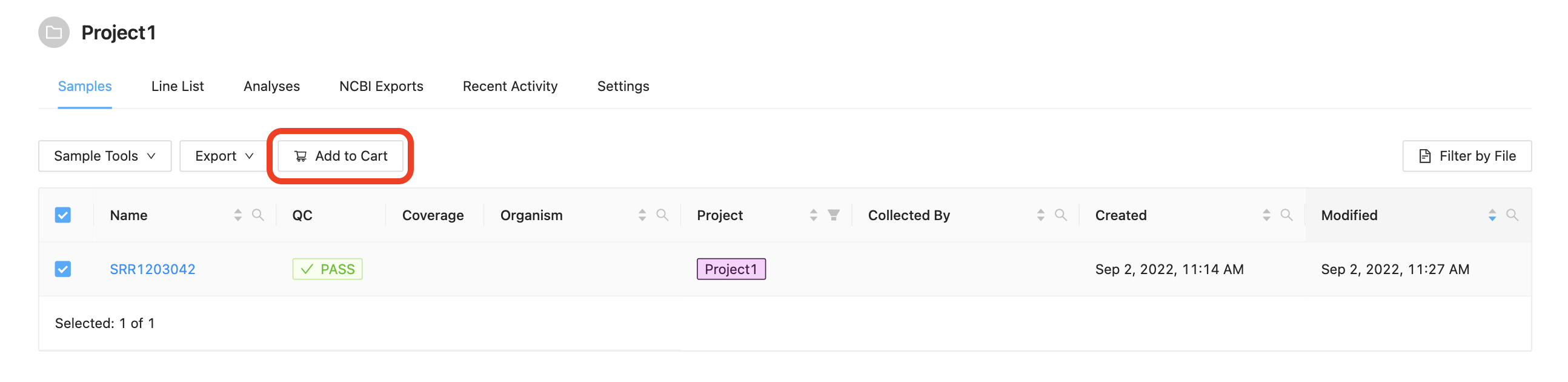
Before a pipeline can be run a set of samples and sequence read data must be selected and added to the cart. For this tutorial please select the single sample and click the Add to Cart button.
Once the desired samples have been added to the cart, click the Cart button at the top navigation bar:
Selecting a Pipeline
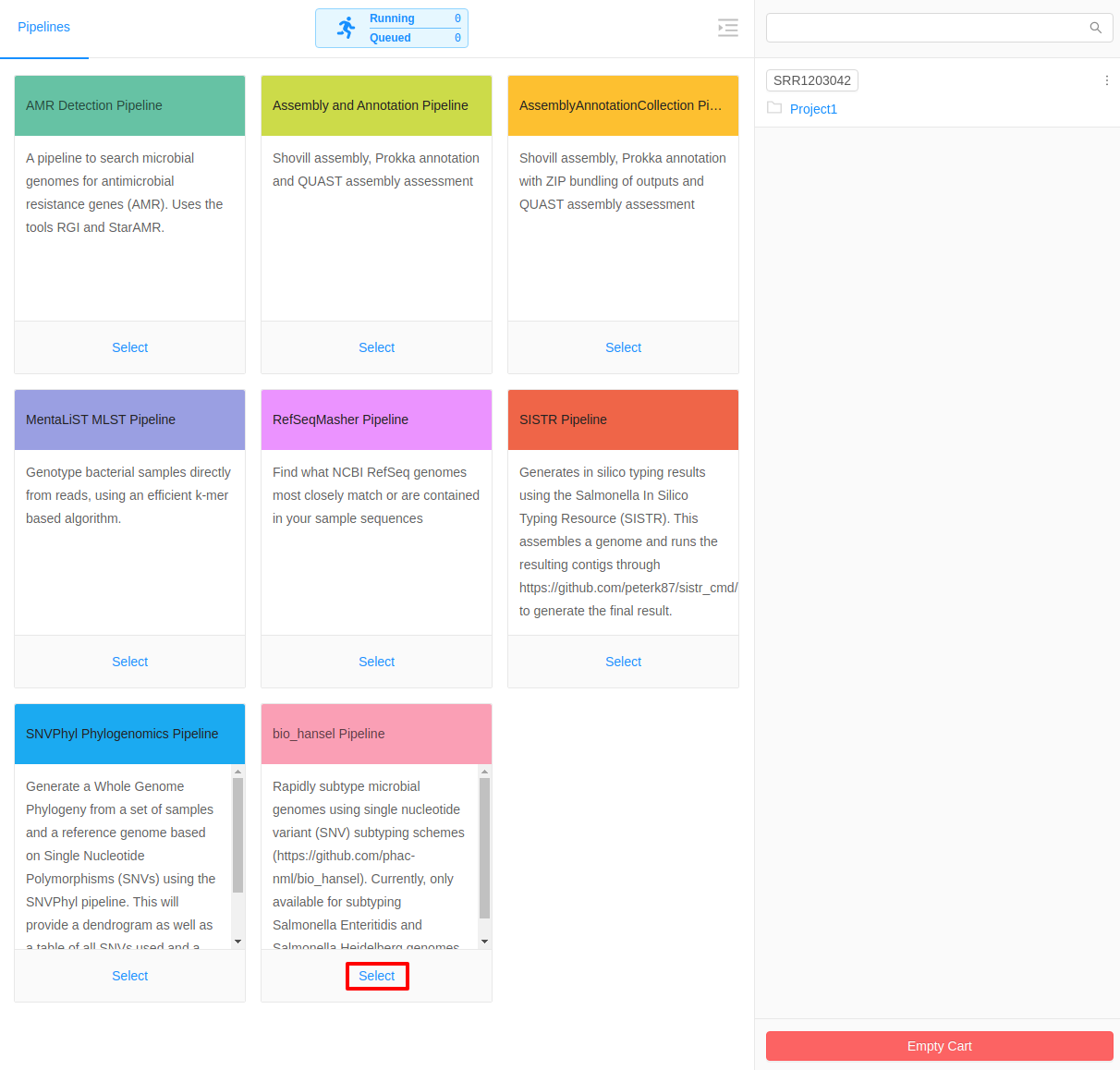
Once inside the cart, the Select a Pipeline button can be used to select a pipeline to run on the selected samples.
For this tutorial, we will select the bio_hansel Pipeline:
Selecting Parameters
Once the pipeline is selected, the next page provides an overview of all the input files, as well as the option to modify parameters. You will be required to select a SNV subtyping scheme to use for your analysis.
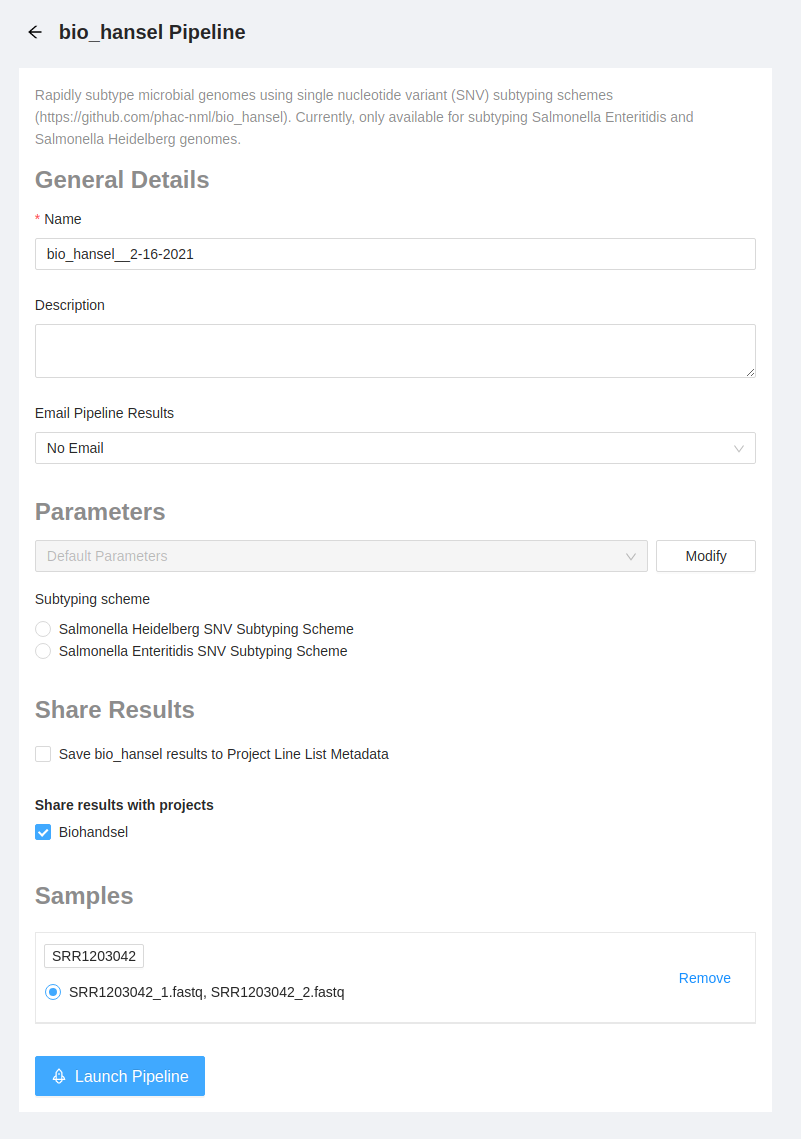
Please select the Salmonella Heidelberg SNV Subtyping Scheme.

You can leave the other parameters unmodified. Please select the Launch Pipeline button to start the pipeline.

Once the button is selected, you will be redirected to the analysis details page.
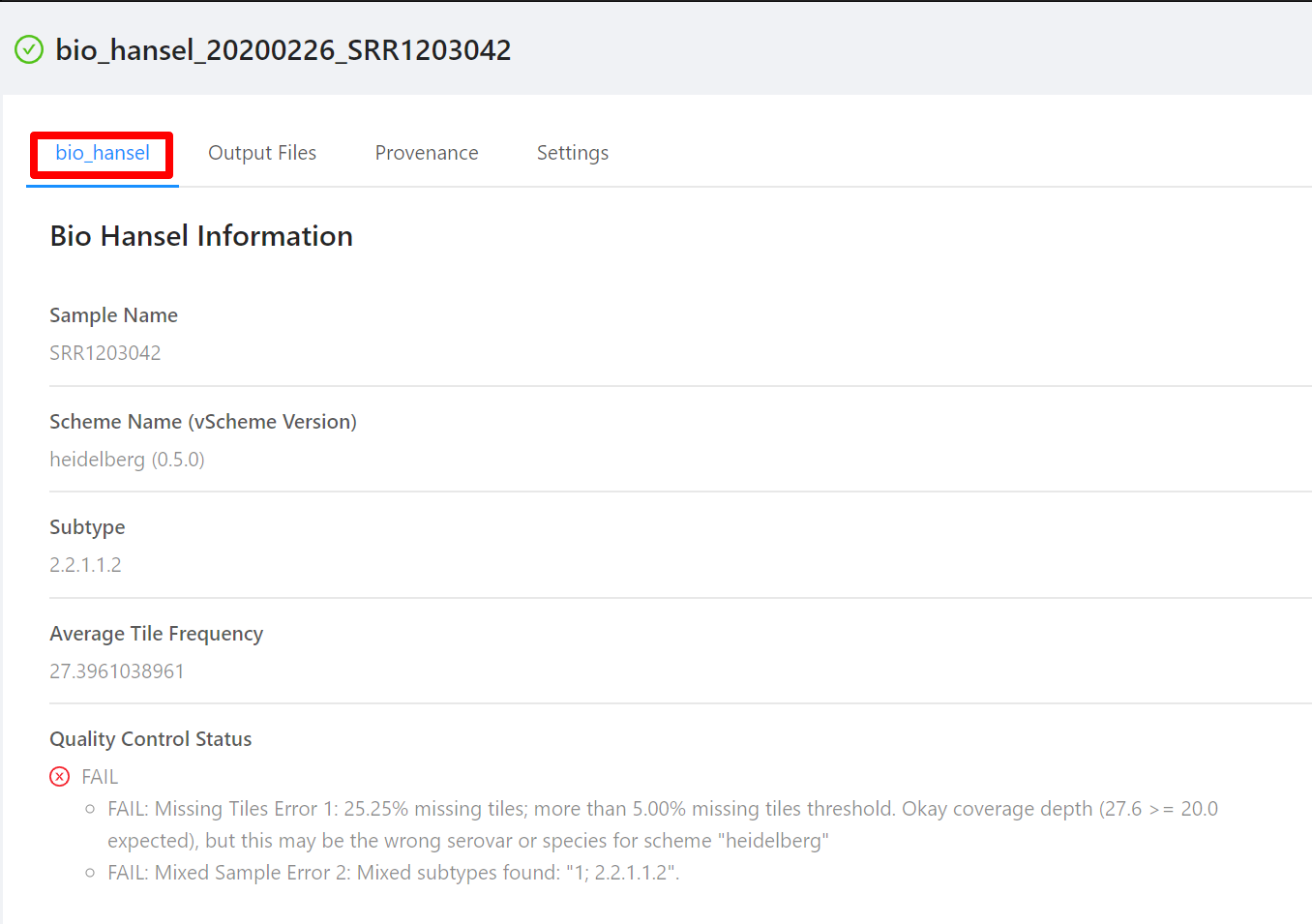
Once the pipeline is complete, you will be able to view the bio_hansel pipeline results.
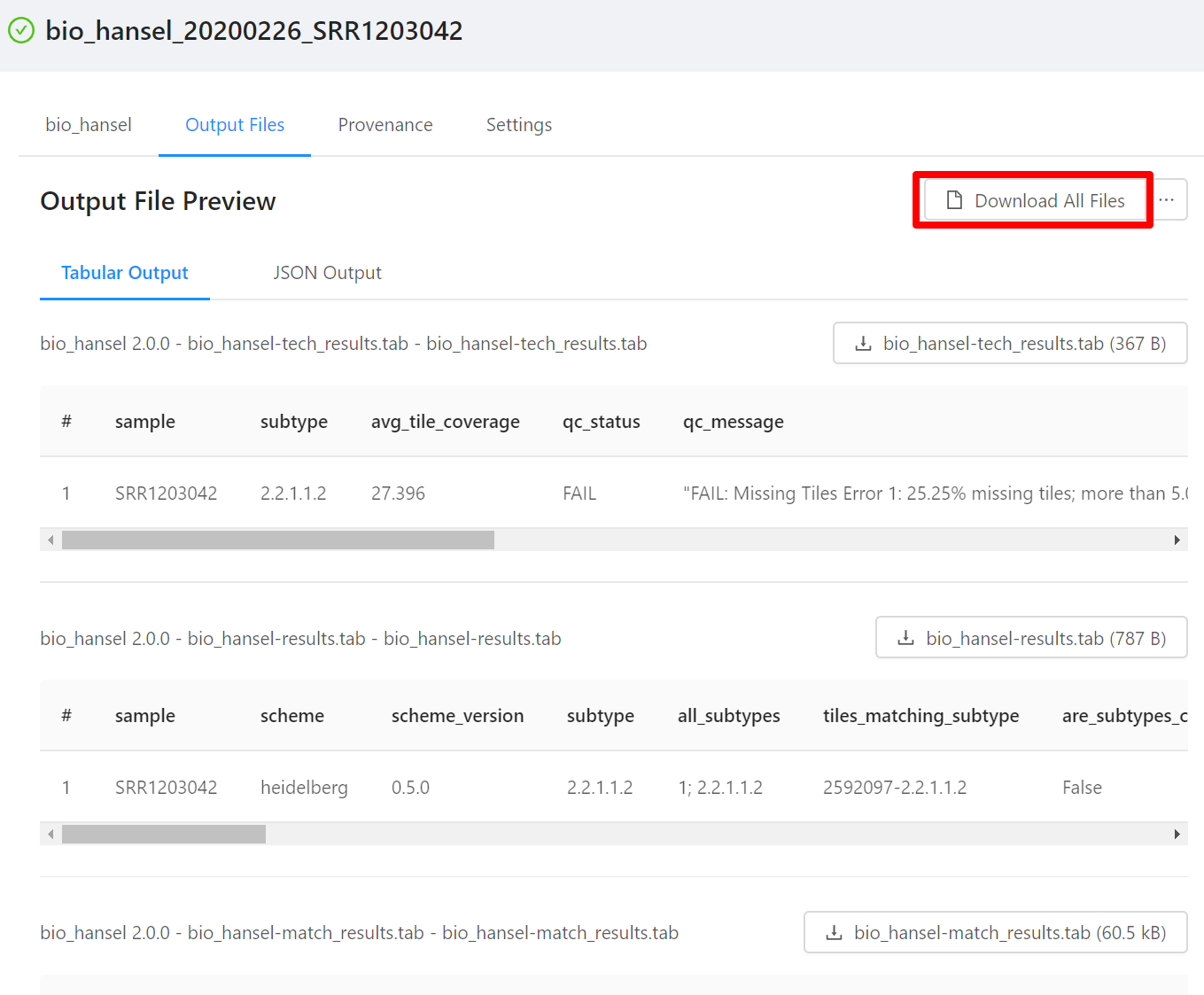
You can view the bio_hansel analysis output files in tabular or json view by selecting the Output File Preview Tab. Note that not all files have an available preview and as such are not displayed in the Output File Preview but are downloaded when selecting the Download All Files button.
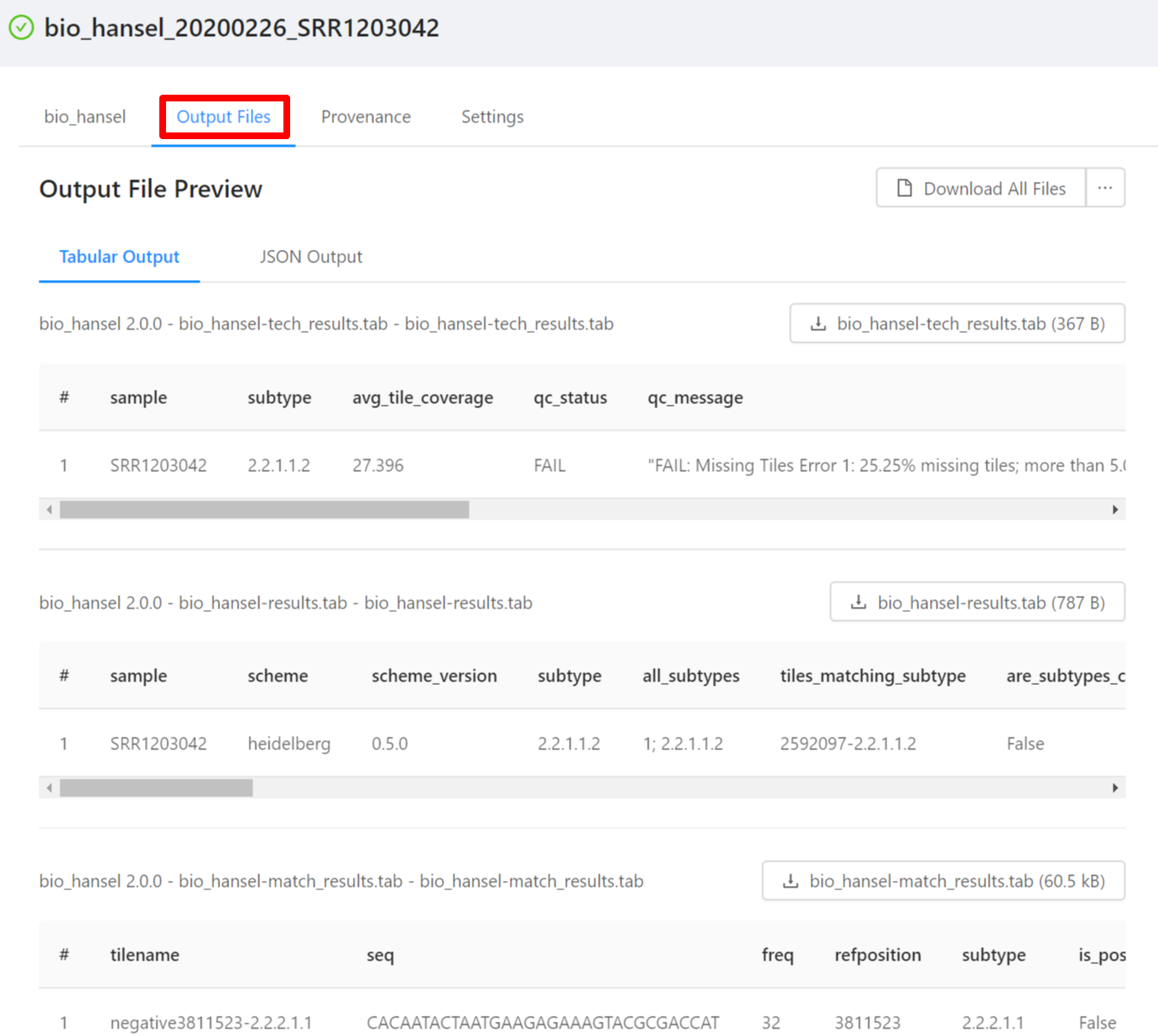
To download individual files select the … next to the Download All Files and select the file to download.
To download al the files generated by the analysis, please select the Download All Files button.
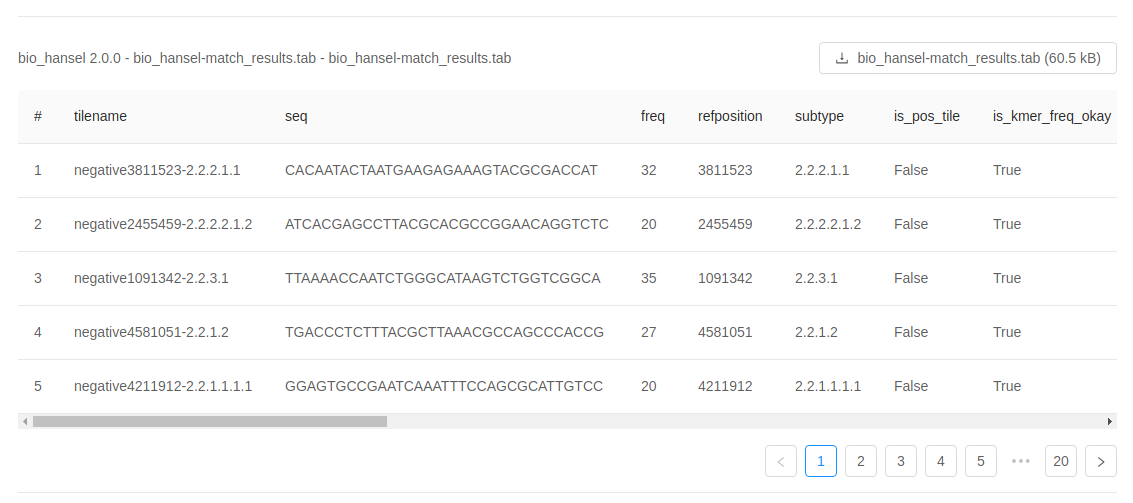
You can view the detailed bio_hansel match results in a tabular view:
Viewing Results For Multiple Samples
If you had checked the Save bio_hansel results to Project Line List Metadata checkbox on the bio_hansel pipeline launch page, you will be able to view the results of your analyses in the Line List table on the Project page:
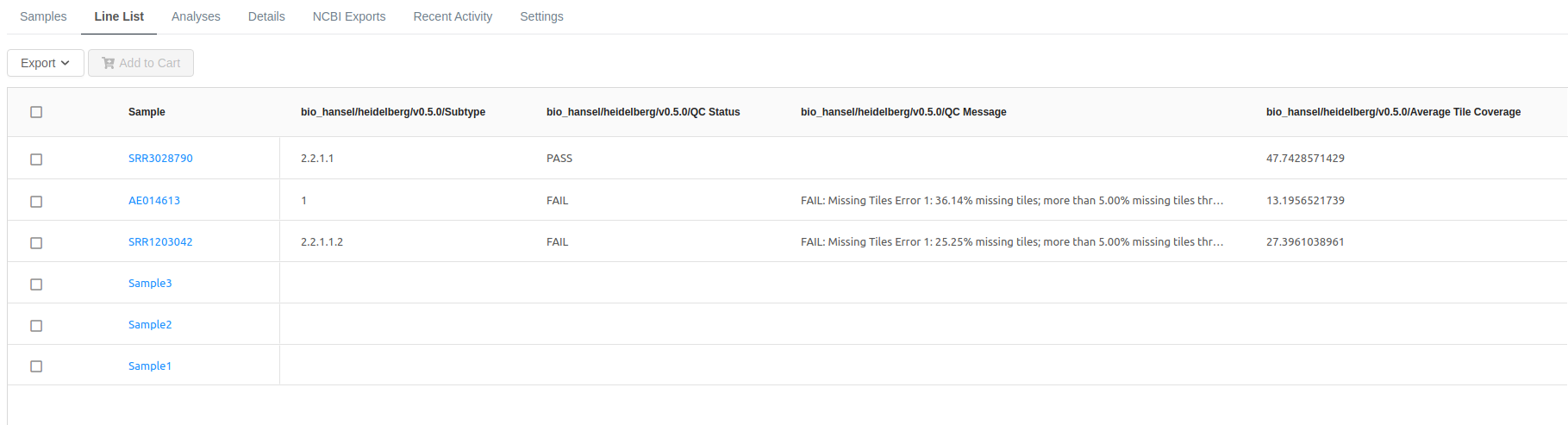
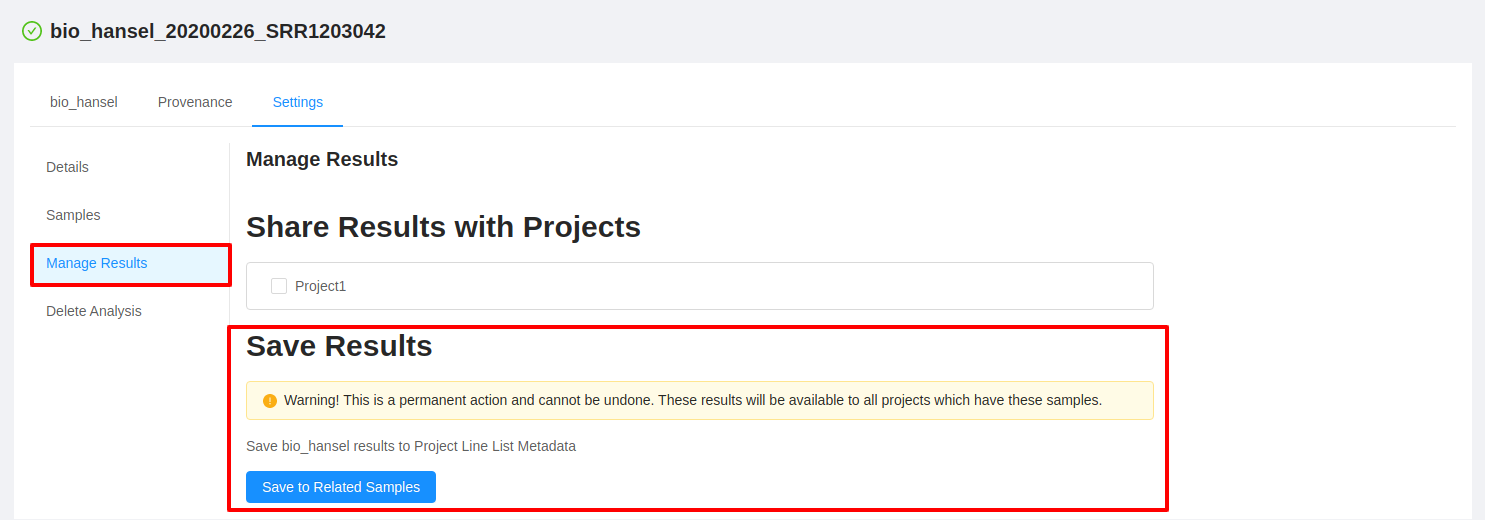
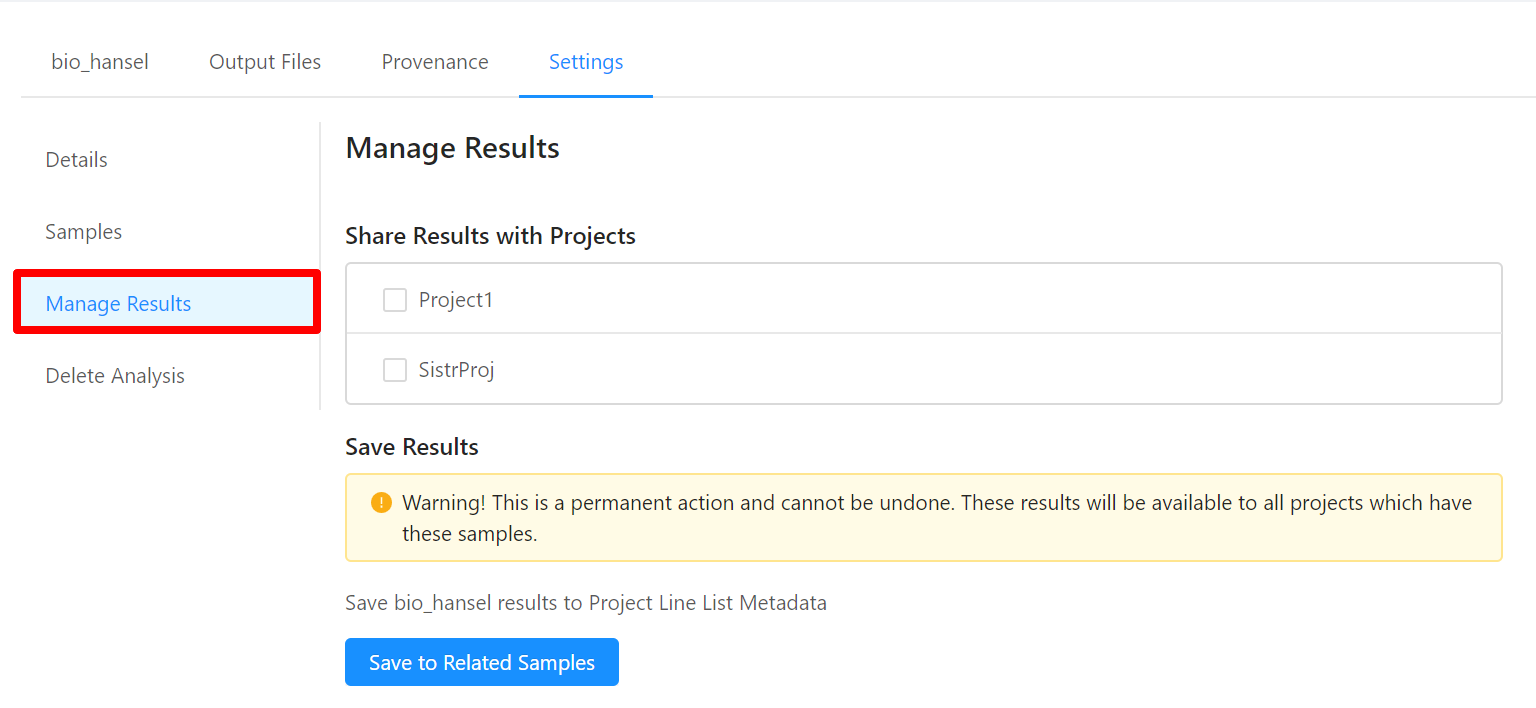
Note that the results can also be saved to the Project Line List Metadata from the Settings > Manage Results tab within your analysis.
Interpreting the Results
For more information on interpreting your bio_hansel results, please see:
- the IRIDA bio_hansel Documentation or
- the bio_hansel GitHub page.
Viewing Provenance Information
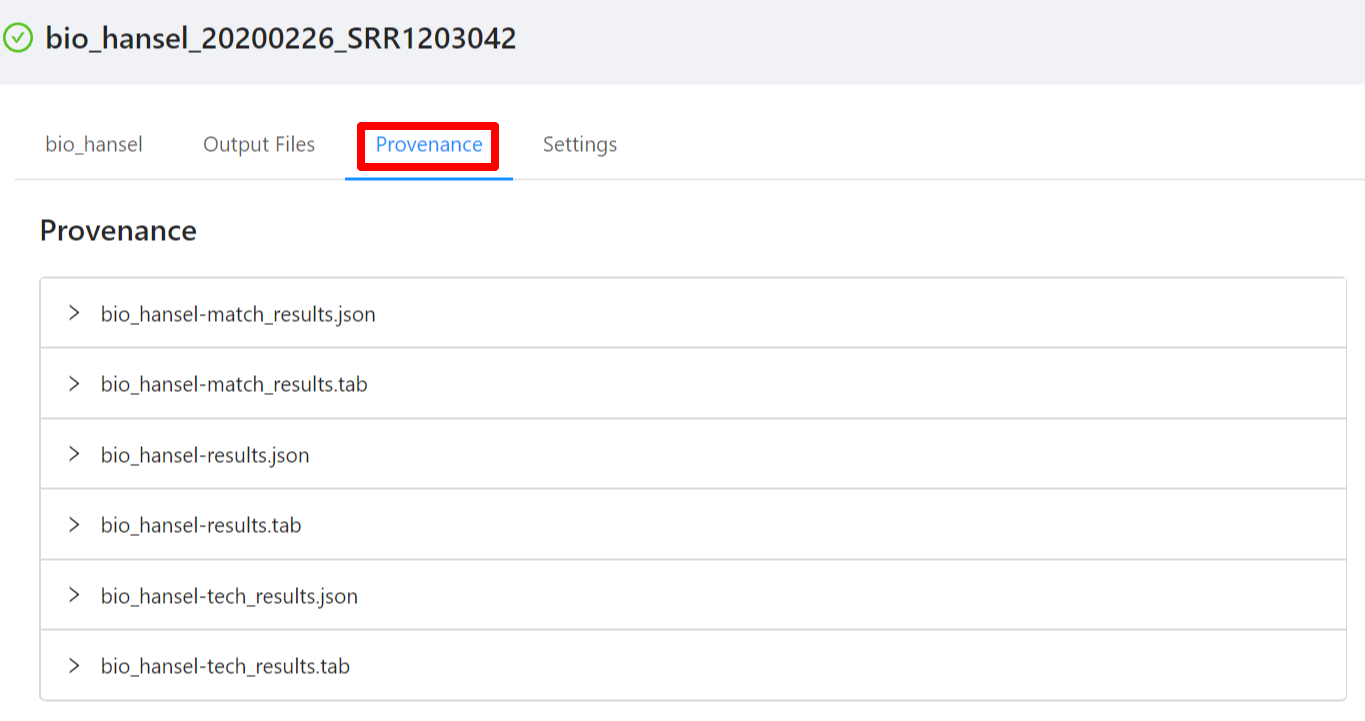
To view the pipeline provenance information, please select the Provenance tab.
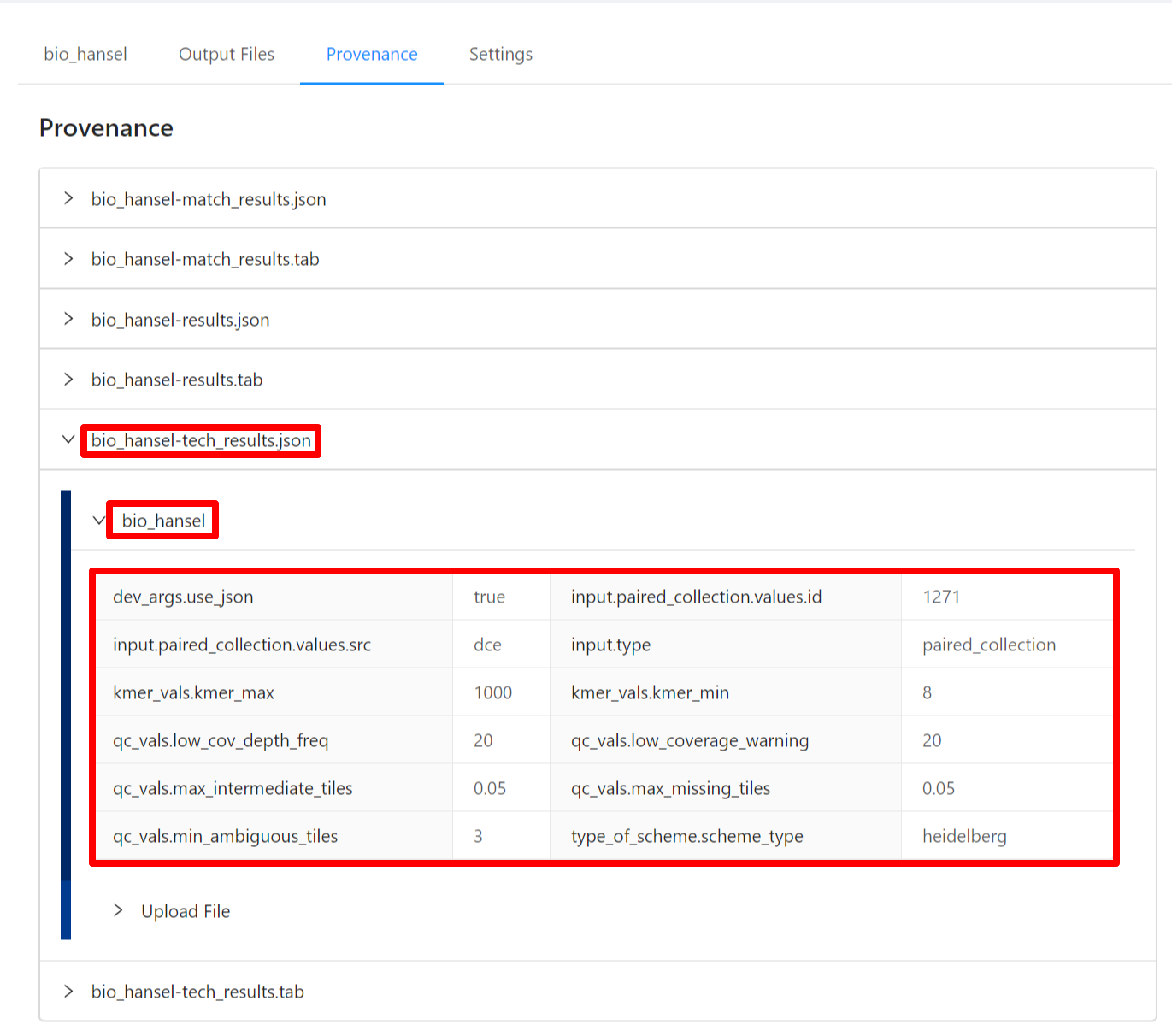
The provenance is displayed on a per file basis. Clicking on bio_hansel_tech-results.json file will display it’s provenance. Expanding each tool will display the parameters that the tool was executed with.
Viewing Pipeline Details
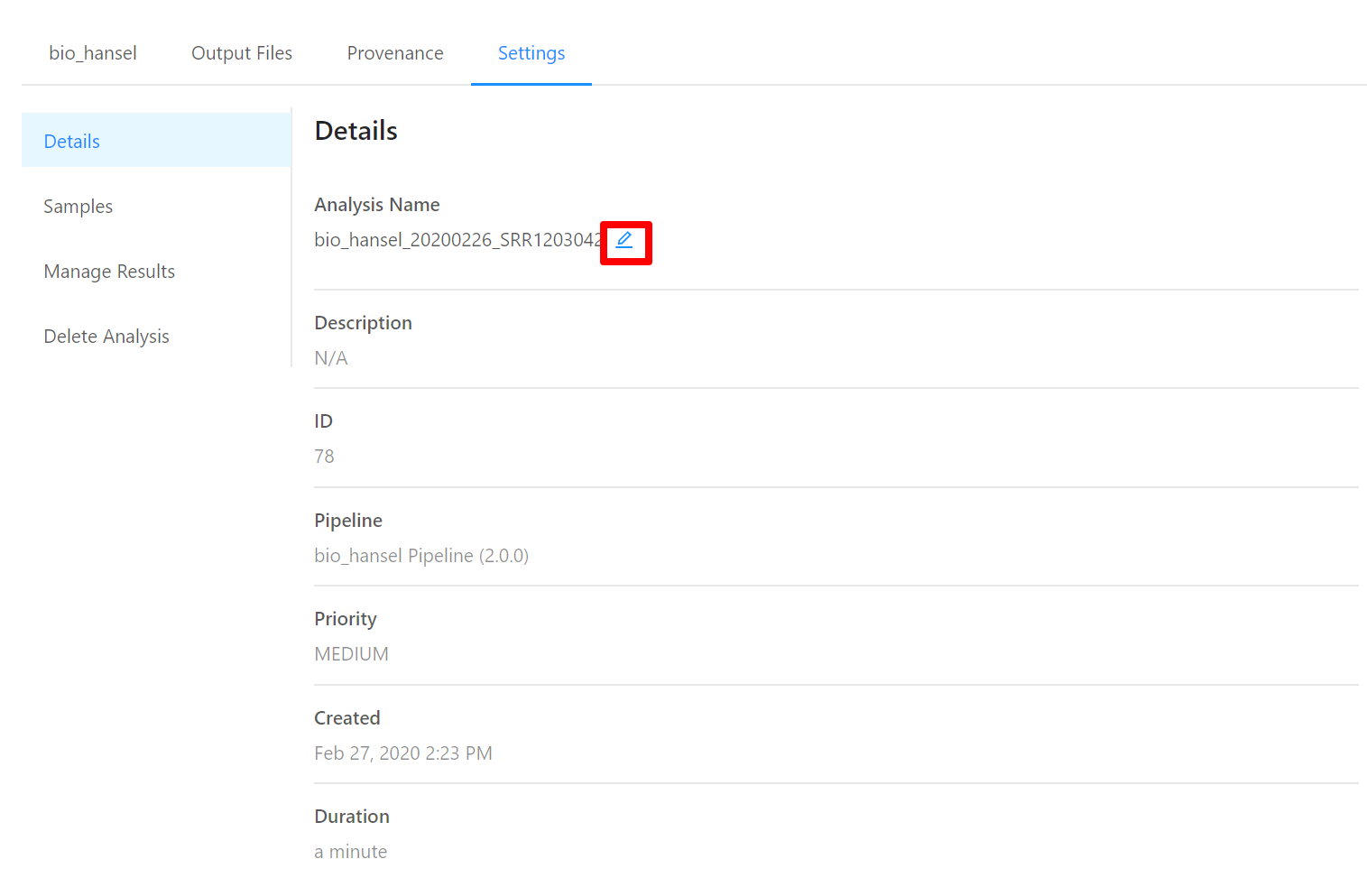
To view analysis details, please select the Settings tab. From here you can view the analysis name, analysis description, analysis id, pipeline and pipeline version used by the analysis, analysis priority, when the analysis was created, and duration of the analysis.
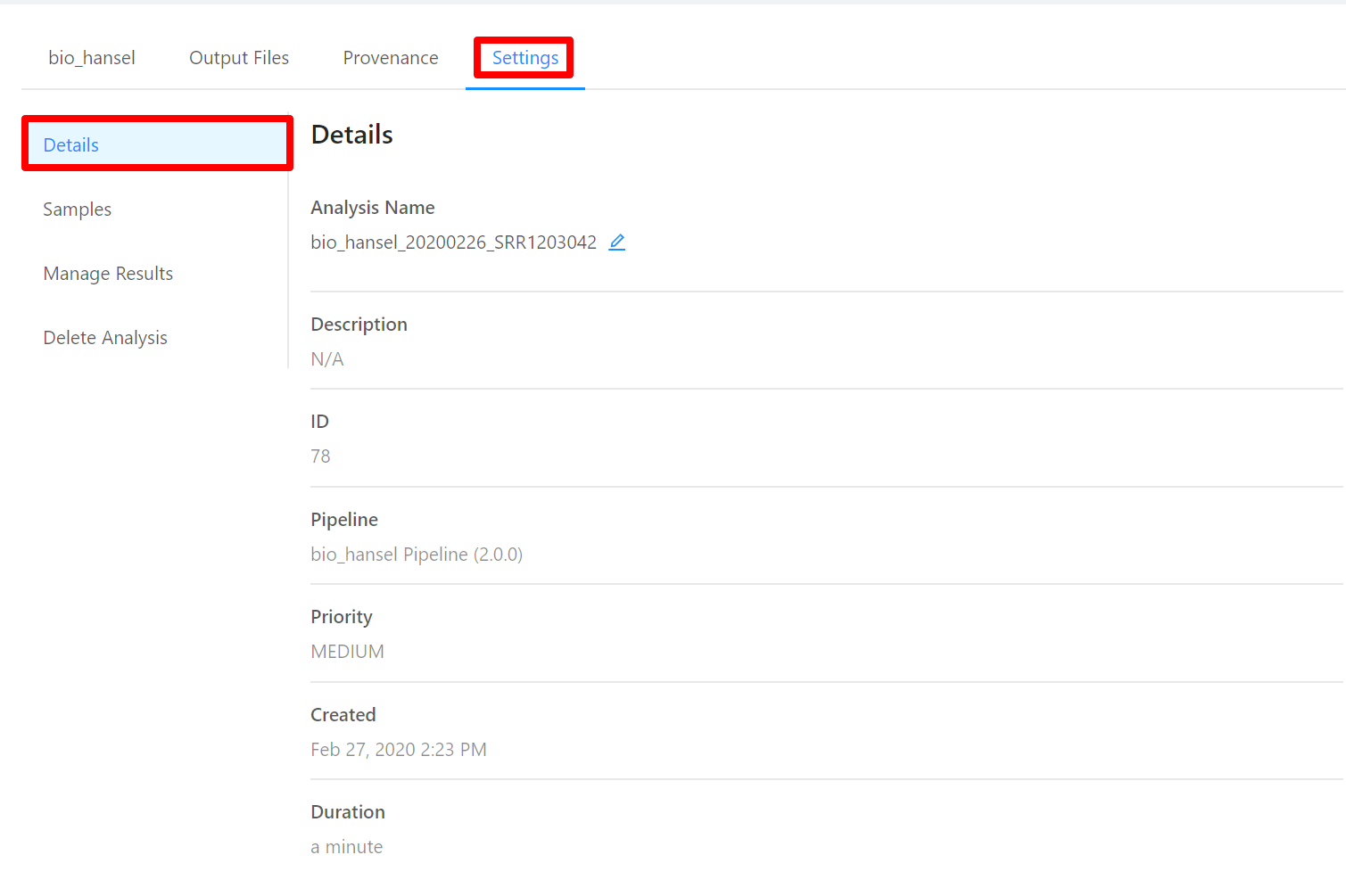
To edit an analysis name, please select the Pencil icon next to the analysis name. Once you have edited the analysis name, pressing the ENTER key on your keyboard or clicking anywhere outside of the text box will update the name. To cancel editing a name you can either hit the ESC key on your keyboard or if the name has not been changed you can also click anywhere outside of the text box.
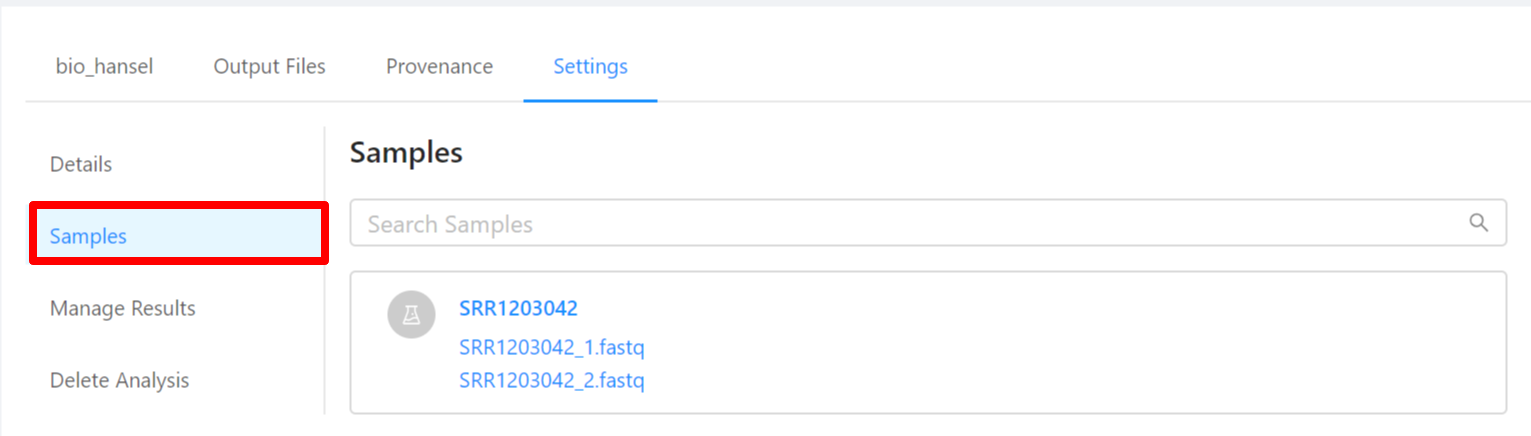
To view samples used by the analysis, please select the Samples tab.
To share analysis results with other projects and/or save results back to samples, please select the Manage Results tab.
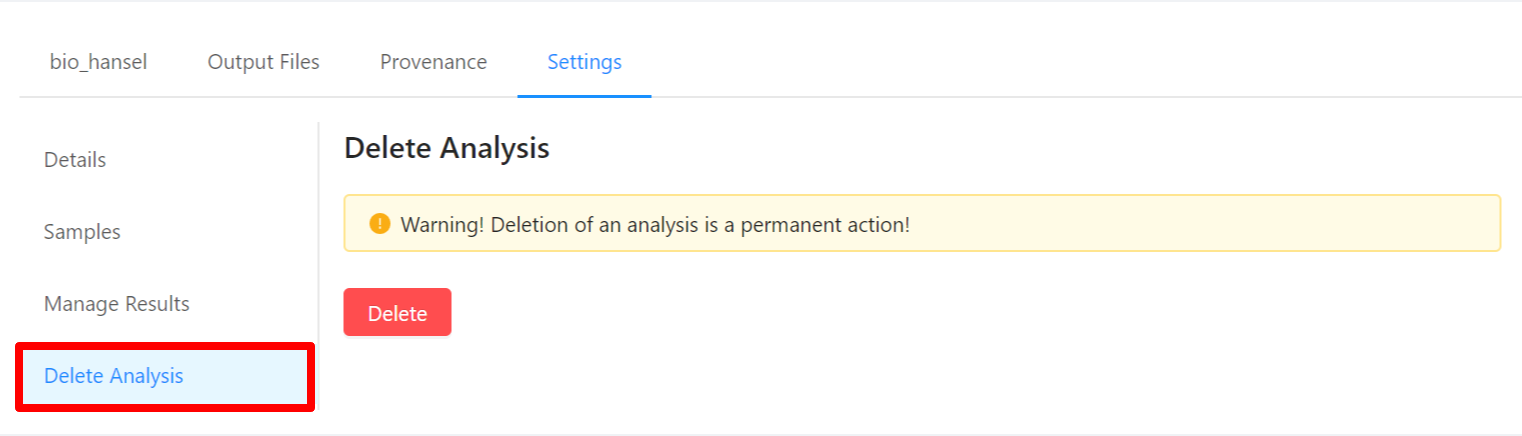
To delete an analysis, please select the Delete Analysis tab.